The task file is the prompt
How a CLAUDE.md and a folder of markdown tasks let a team share context and hand work to AI agents — version-controlled, vendor-independent, and with nobody writing prompts.
Working with AI on a real project, day to day, quietly turns into a coordination problem. Someone spots a thing that needs doing. They open a chat, re-explain the project, think up the right prompt, phrase it, paste in the relevant files, and wait. Tomorrow a teammate does the same dance from scratch — same context re-typed, a slightly different prompt, a slightly different result.
The work isn't the bottleneck. The re-explaining is. So I stopped explaining to the AI and started writing it down once, in the repo, where both the humans and the agents already look.
Two files do most of the work
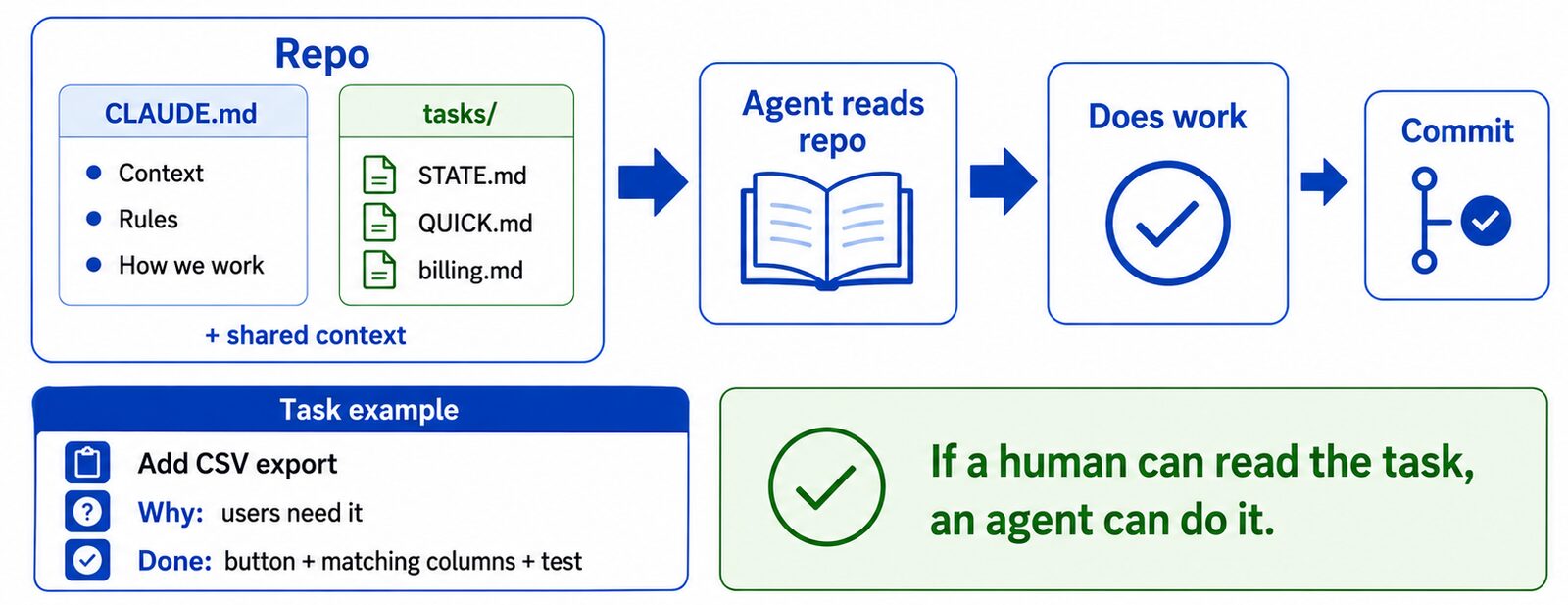
The whole system is two things that live in the codebase and travel with it through git.
A CLAUDE.md at the root — the standing context. What the project is, the non-negotiable rules, how we build, where the tasks are, a quick map of the repo. An agent reads it first and inherits the same constraints every teammate works under. It's the onboarding doc you never have to give twice.
# CLAUDE.md — how we work in this repo
## What this is
One paragraph an agent can absorb in five seconds.
## Non-negotiable rules
- Never touch X without Y.
- Migrations are append-only.
## How we build
Stack, conventions, what "done" means, how to run the tests.
## Where the tasks live
docs/tasks/ — read STATE.md first, then pick one.
## Repo map
src/… · migrations/… · docs/…A folder of tasks — the living backlog, also in markdown. Start with one file; split it as it grows.
docs/tasks/
STATE.md # the big picture: what's done, what's next, by area
QUICK.md # small things, feedback, one-liners
billing.md # grouped by type once a single file gets noisyThe loop, minus the prompting
Once the context and the backlog are in the repo, the day-to-day collapses into something almost boring:
- You notice work that needs doing.
- You write it as a task and commit it. That's the whole "assignment."
- A teammate opens the repo and tells their agent: pick up the next task.
- The agent reads
CLAUDE.mdand the task files, does the work, ticks the box, and commits.
Nobody wrote a prompt. Nobody re-explained the project. The person who spotted the work didn't have to be the person who did it, and didn't have to be available when it got done. The task was the instruction — which is exactly why it has to be written like one.
If a teammate can read the task and know what "done" looks like, so can an agent. If they can't, neither can the agent.
A task that works looks less like a wish and more like a small contract — goal, why, and a checkable definition of done:
## Add CSV export to the reports page
Status: todo
Why: people keep asking for it.
Done when:
- there's a "Download CSV" button on the reports page
- the columns match the on-screen table exactly
- it's covered by a test
Context: the existing PDF export is the closest pattern to copy.This is the same idea as turning a prompt into a loop: the value isn't in the cleverness of the phrasing, it's in stating the goal, the constraints, and how you'll know it's finished. Write the task that well and the prompt writes itself.
You don't even have to write the task
Put that format — the task "contract" — into CLAUDE.md itself, and the human stops writing tasks at all. You just tell your agent "add a task to let users export reports as CSV," and the agent, which already knows where the tasks live and what shape a task should take, writes it out for you: well-phrased, in the right format, in the right file. If something's missing — a why, a definition of done — it asks you before committing it.
So the floor drops one more level. You describe the work in a sentence; the agent turns it into a proper task; the next agent picks it up and does it. You can still hand-write a task when you want the wording exactly so — but you no longer have to, and the format stays consistent no matter who (or what) wrote it.
Why markdown and git, not a board
You could keep all of this in a project-management tool, and if your company lives in Jira there are agent skills that read tasks straight from it. But putting it in the repo buys things a board can't:
- It's where the agent already is. No integration, no API token, no third party between the work and the code.
- It versions with the code. The task, the commit that did it, and the change all sit in the same history.
git blameon a decision actually works. - It's diffable and reviewable. Adding work is a commit. Changing scope is a diff. Disagreeing is a comment on a line.
- It's vendor-independent. No seat, no migration, no outage that takes your backlog offline.
Letting it grow
It starts as a single TASKS.md and that's enough for a while. When one file gets noisy, split by intent rather than by person: a STATE.md for the big moving picture, a QUICK.md for small feedback, a file per area when an area earns one. The structure should mirror how you actually think about the work, not an org chart.
And keep it from bloating. Once a task is done, either delete it — the git history already remembers it ever existed — or move it to a DONE.md if you want a visible record of what shipped. Both are fine; the only real mistake is letting finished work pile up until the file an agent has to read is mostly noise.
The point isn't the folder layout. It's the shift underneath it: the shared context stops living in people's heads and DMs, and starts living in the repo as plain text that humans write and agents execute. Humans decide what and why; the agents handle a lot of the how; and the handoff between them is just a commit.